VTuberのLive2Dモデルを作成するときに必要なキャラクター画像を描くのは大変ですよね。
しかし、Stable Diffusionなどの画像生成AIツールを使えば、画力がなくても自動的にキャラクターを生成できます。
とはいえ、AIツールを使ったことがなければ以下のような疑問が出るでしょう。
- Stable Diffusionで簡単に作れるの?
- どうやって使えばいいの?
- PCスペックや料金はどのくらい必要?
結論から言うと、Stable Diffusionはオンラインで無料利用できるうえ、ローカル環境を用意すれば幅広いカスタマイズも可能です。
今回はStable DiffusionでLive2D用の画像を生成するまでの具体的な手順を分かりやすく解説します。
VTuberモデルを自作したいクリエイターや配信者の方は、ぜひ本記事を最後までご覧ください。
Stable Diffusionとは?4つの特徴

Stable Diffusionとは、Stability AI社が開発している画像生成AIツールです。
ここでは、Stable Diffusionの代表的な特徴を以下の順で解説します。
- プロンプトだけで画像を生成できる
- オンラインやローカル環境で利用できる
- 無料から利用できる
- モデルなどカスタマイズが可能
1.プロンプト(テキスト)だけで画像を生成できる
Stable Diffusionは、ユーザーが入力したプロンプト(テキスト)を解析して画像を生成するツールです。
プロンプトには「1人の女性」のような短い文章から「教室の机で鉛筆を持ちながら困った表情をしている黒いロングヘアで学生服の少女」のような長い文章まで入力できます。

入力したプロンプトは学習済みモデルによって文脈を読み取られ、高精細なイラストや写真風アートが最短数秒で出力されます。
プロンプトを変えるだけで大量のバリエーションを得られるため、効率的にLive2Dキャラクターを作れるでしょう。
2.オンラインやローカル環境で利用できる
Stable DiffusionはWebブラウザ上のオンラインサービスや、自分のPCにインストールしたローカル環境で利用できます。
オープンソースで公開されているStable Diffusionは誰でも利用できるため、以下のように多くのオンラインサービスで使われています。
- Stable Diffusion Online
- DreamStudio
- Mage.space
- リートン
大抵のオンラインサービスには制限がかかっており、設定できる内容や利用回数などが限られている点が欠点です。
一方、ローカル環境で利用する場合はさまざまな設定項目を変更できるうえに、生成する回数に制限がありません。
短時間で多くのパターンを試したいのであれば、自分でローカル環境を構築するのがおすすめです。
3.無料から利用できる
オンラインでもローカル環境でも、Stable Diffusionを無料利用することが可能です。
オンラインの場合はアカウントを作るだけで決まった回数だけ画像を生成できるサービスが多いです。
ローカル環境は準備が少々手間ですが、一度構築できれば料金をかけずに制限なく生成できます。
ただし、要求されるパソコンのスペックが高めだったり、電気代がかかったりする点には注意が必要でしょう。
4.モデルなどカスタマイズが可能
Stable Diffusionはモデルデータや拡張機能を選択することで、出力内容をカスタマイズできます。
とくにローカル環境は、ネット上で配布されているデータを自由に導入できる点が強みです。
たとえば、アニメ絵に特化したモデルを使ったり、ポーズを指定する拡張機能を使ったりすることで、Live2D用の画像が生成しやすくなるでしょう。
学習に使う画像を大量に用意すれば、自分でモデルを作ることも可能です。
Live2D用の画像を無料でAI生成する手順

Live2Dパーツ用の立ち絵をオンラインサービスだけで生成する方法を、以下の流れで説明します。
- Stable Diffusion Onlineでログインする
- プロンプトを入力する
- スタイルやアスペクト比を変更する
- 生成ボタンを押す
STEP1.Stable Diffusion Onlineでログインする
Stable Diffusion Onlineのサイトにアクセスし、作成したアカウントでログインします。
Googleアカウントまたはメールアドレスを使ってアカウントを作成してください。
登録が完了するとダッシュボード画面が開き、画像を生成できるようになります。
STEP2.プロンプトを入力する
画面左上のテキストボックスに、生成したいキャラクターの説明を入力します。
Live2Dで使う画像を生成する場合、以下のような単語を書くと良いでしょう。
- standing pose(立ち絵)
- front view(正面からの視点)
- whole body(全身)
- white background(白い背景)
上記に加えて、キャラクターの性別や服装、描き方といった要素を盛り込んでみてください。
プロンプトのコツ
プロンプトの書き方は基本的に自由ですが、以下の点を押さえておくと良い結果を得やすいです。
- 英語で記述する(DeepLなどで翻訳する)
- 優先したい要素を先に書く
- 否定的なプロンプト(ネガティブプロンプト)を追加する
- 別の言い方を考える
日本語では伝わらない場合がほとんどなので、英語での記述はとくに重要です。
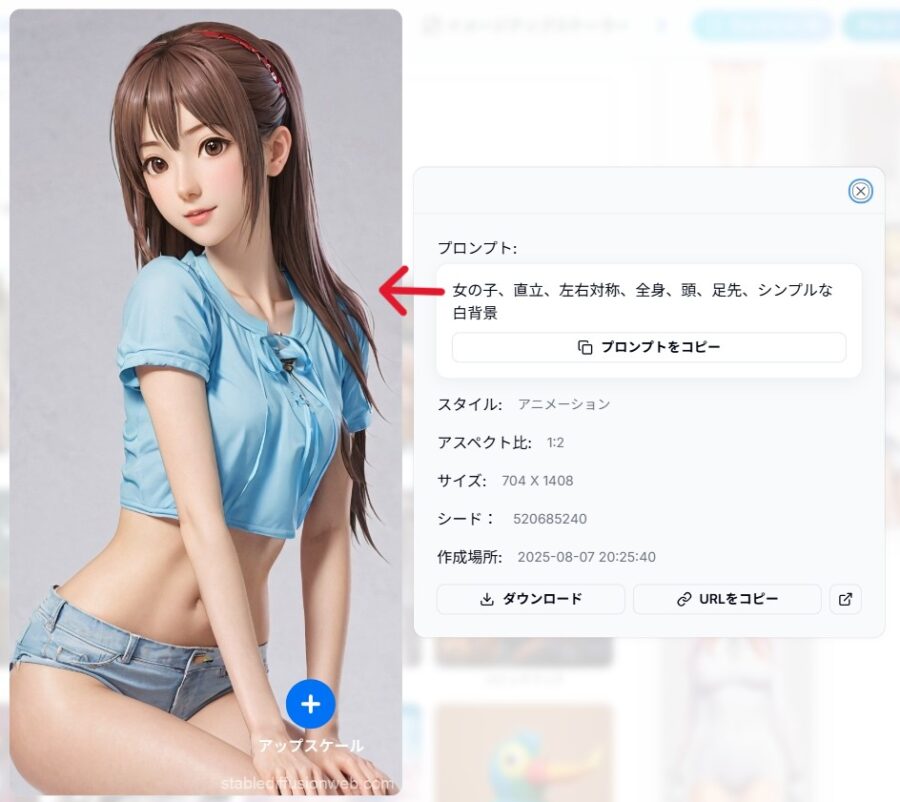
そもそもAIが学習していない内容は出力できないので注意しましょう。
STEP3.スタイルやアスペクト比を変更する
プロンプト入力欄の下にある各設定を変更します。
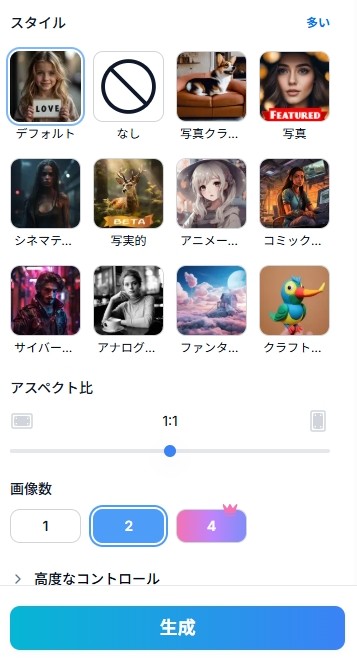
Live2Dを使うのであればアニメ系イラストが向いているので、スタイルは「アニメーション」がおすすめです。
また、キャラクターの立ち絵は縦長になりやすいため、アスペクト比は「5:12」などの縦長を選択しましょう。
画像数は選んだ数だけ画像を生成しますが、同じ数のクレジットを消費するので注意してください。
高度なコントロールは一旦スルーしてOKです。
STEP4.生成ボタンを押す
設定が完了したら「生成」ボタンを押してください。
ボタンを押すとクレジットが消費され、プロンプトに則った画像の出力が始まります。
数十秒ほど待つと結果が出力されるので、意図した内容であるかチェックしましょう。
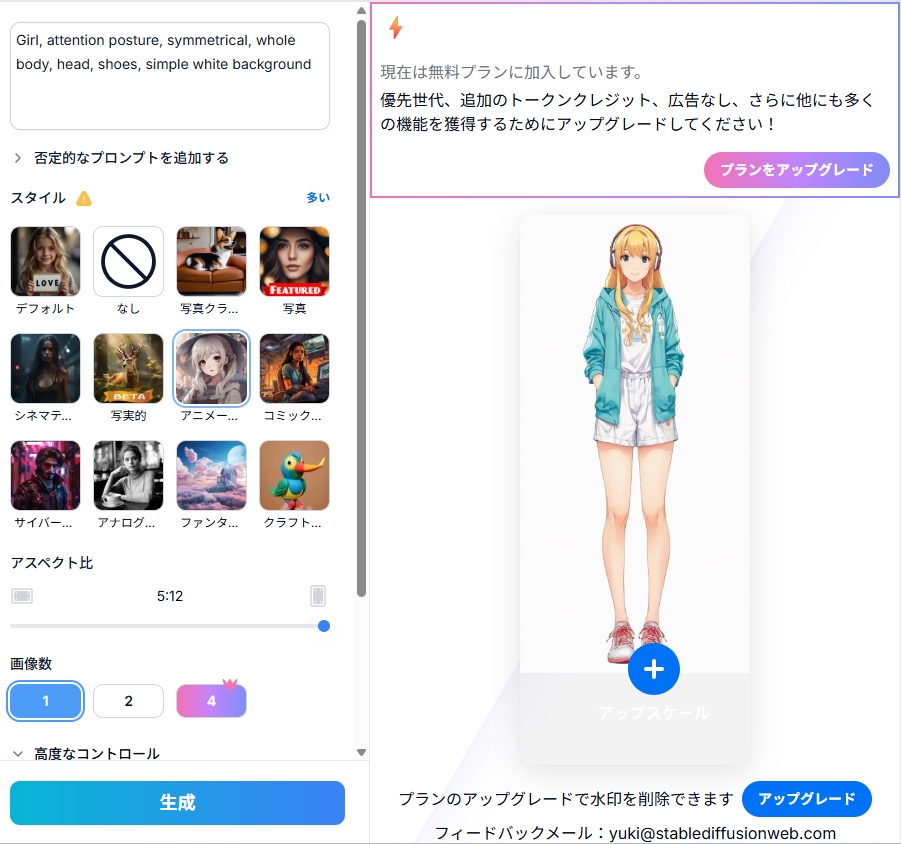
満足いく結果が出力されたら画像を選択し、ダウンロードしましょう。
出力内容に不満があれば、再度生成して違うパターンを試してみてください。
高度なコントロールでシードを固定しなければ、生成するたびに異なる結果が出力されます。

NSFW画像は出力できない
Stable Diffusion Onlineをはじめ、ほとんどのオンラインサービスでNSFW画像は生成できません。
NSFWはNot Safe For Workの略で、職場での視聴に適さないコンテンツ(暴力的、性的など)を指します。
また、2025年7月31日から発効しているStability AIの利用規約によると、性的なコンテンツの生成は明確に禁止されています。
We Prohibit Sexually Explicit Content.
This includes using Stability Technology to facilitate:
引用元:Stability AI|Acceptable Use Policy
- non-consensual intimate imagery (NCII).
- illegal pornographic content.
- content relating to sexual intercourse, sexual acts, or sexual violence.
上記規約が適用されないケースもあるそうですが、商用利用するのであればNSFW画像は避けるのが無難でしょう。
ローカル環境に導入する手順

スペックが十分なパソコンを持っている場合、ローカル環境にStable Diffusionを導入するとメリットが多いのでおすすめです。
以下では、多くのユーザーがローカル環境で利用している、AUTOMATIC1111版Stable Diffusion WebUIの導入方法を解説します。
- Pythonをインストールする
- Gitをインストールする
- stable-diffusion-webuiリポジトリを複製する
- 必要なモデルをダウンロードする
- webui-user.batを実行する
STEP1.Pythonをインストールする
Stable Diffusionを動作させるのに必要なPythonをインストールします。
公式サイトで、バージョン3.10.x のインストーラーをダウンロードしてください。
3.11以降のバージョンはStable Diffusionに対応していないので注意。
ダウンロードしたインストーラーを実行し、インストールを進めていきます。
途中で「Add Python to PATH」のチェックボックスがあるので、忘れずにチェックを入れてください。
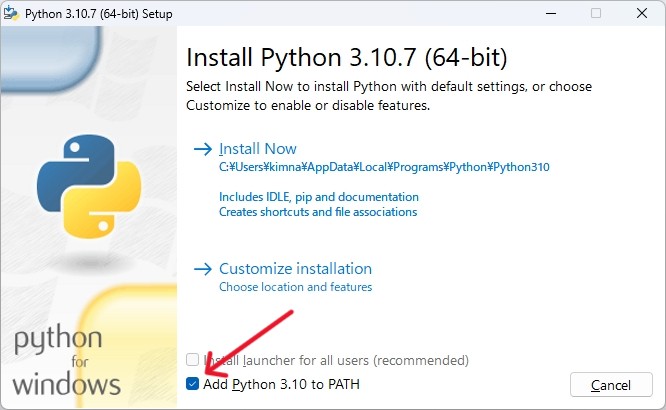
インストール後にコマンドプロンプトで「python –version」を打ち、インストールしたバージョンを確認できればOKです。
STEP2.Gitをインストールする
この後の作業をスムーズに進められるようにGitをインストールします。
公式サイトから最新バージョンをダウンロードしましょう。
ダウンロードしたファイルを実行し、デフォルトのままインストールを進めてください。
Gitのインストールが完了すれば、右クリックメニューにGit関連の項目が追加されます。
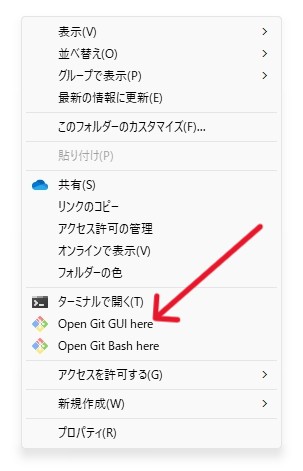
STEP3.stable-diffusion-webuiリポジトリを複製する
Gitを使い、Stable Diffusion WebUIのファイルを複製します。
任意のフォルダで右クリックし、「Open Git Bash here」を選択してください。
するとターミナルが開くので、以下コマンドを入力しましょう。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitこのコマンドを実行すると、右クリックした任意フォルダの中に必要なファイルがコピーされていきます。
処理が終了するまで、ターミナルを開いたまま待ちましょう。
STEP4.必要なモデルをダウンロードする
先にSTEP5を実行しておくと効率よく進められます。
画像生成に必須のモデルデータ(Checkpoint)をダウンロードします。
モデルをダウンロードできるプラットフォームとして有名なのはCivitaiです。
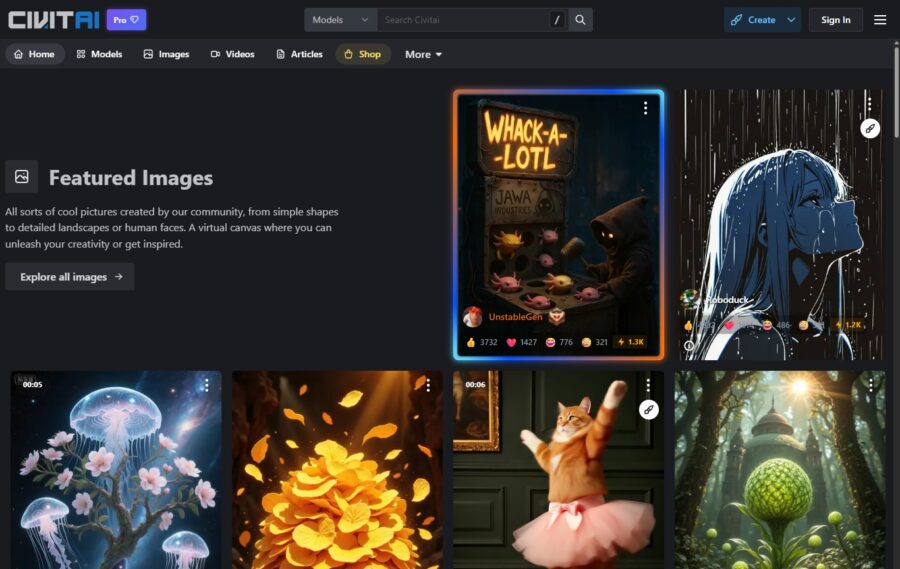
Civitaiにアクセスし、メニューから「Models」を選択してモデルを探してください。
一覧のフィルター(Filters)で、Model typesを「Checkpoint」に指定すると、画像生成用のモデルを探しやすくなります。
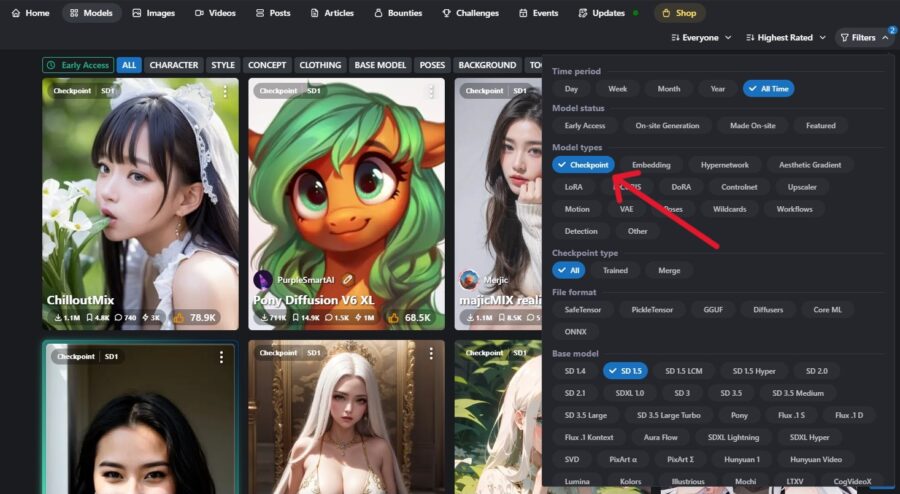
気になるモデルを見つけたらクリックして詳細画面に移動し、ダウンロードボタンを押して入手します。
商用利用の可否はモデルによって異なるため、ダウンロード前にライセンスなどを確認しておくのがおすすめです。
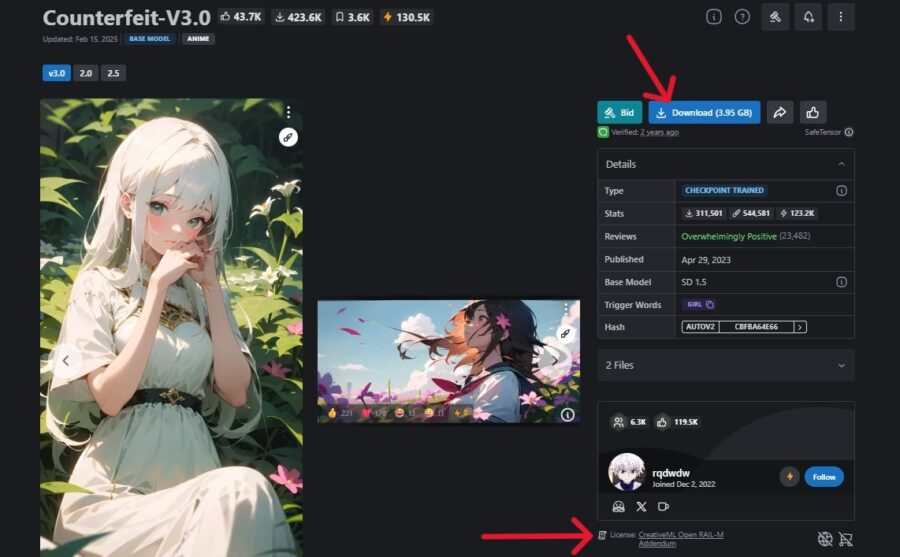
入手したモデルは、STEP3で複製したフォルダ内のmodels/Stable-diffusionへ移動させてください。
モデルのダウンロードにアカウント登録は不要
モデルをダウンロードする目的であれば、Civitaiでアカウントを作る必要はありません。
ただしアカウントを作成すると以下のような機能を利用できるようになります。
- 画像やモデルの表示設定を変更できる
- プラットフォーム内通貨Buzzを獲得できる
- 画像やモデル、コメントなどを投稿できる
- コンテストやバウンティに参加できる
興味があればアカウントを作成すると良いでしょう。
STEP5.webui-user.batを実行する
複製したフォルダの中にあるwebui-user.batファイルをダブルクリックして実行します。
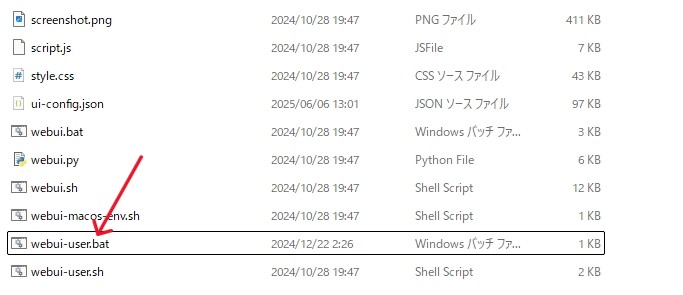
初回起動時は必要なファイルを取得するのに時間がかかるため、数分ほど待ちましょう。
処理が完了するとStable Diffusion WebUIが起動し、ブラウザで自動的にページが開きます。
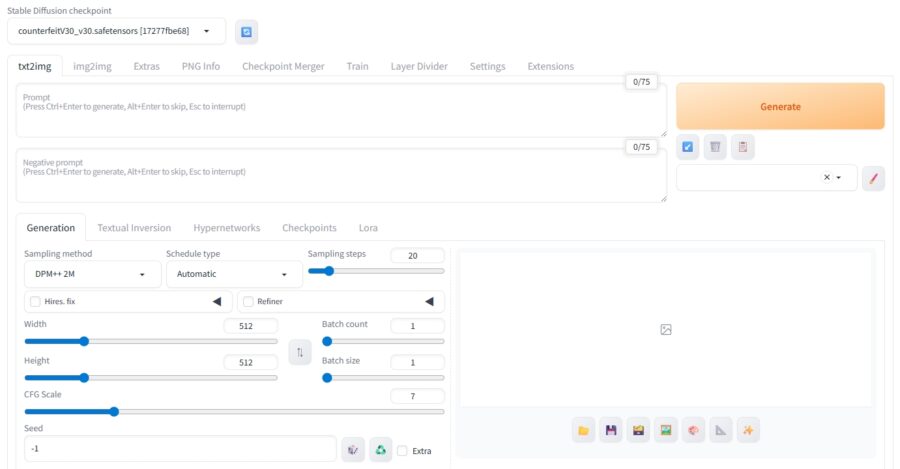
モデルが正しく配置されていれば、プロンプトを入力して生成ボタンを押すだけで画像が生成できます。
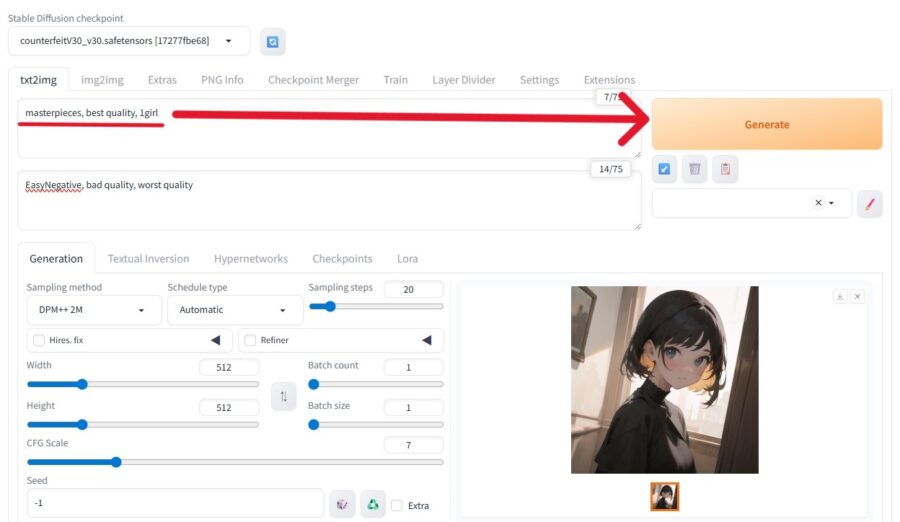
日本語表示にするには
Stable Diffusion WebUIの初期設定は英語ですが、日本語表示に変えることも可能です。
WebUIを起動したら、以下の手順で日本語化しましょう。
- 「Extensions > Avaliable」で「localization」チェックを外して「Load from」ボタンを押す
- 表示される一覧から「ja_JP Localization」を探して「Install」ボタンを押す
- 「Settings > User interface」内のLocalizationで「ja_JP」に変更する(要リロード)
- 「Apply settings」ボタンを押したあとで「Reload UI」ボタンで再起動する
詳細は日本語化ファイルの説明ページで確認してください。

Stable Diffusionに関するQ&A

Stable Diffusionに関する、よくある質問と回答を紹介します。
- スマホでも使えますか?
- どんなスペック・環境が必要ですか?
- インストール時にエラーになります
- おすすめのモデルは?
- 画像に満足できない場合の改善策は?
スマホでも使えますか?
オンライン版であれば、スマホのブラウザやアプリから利用できます。
ローカル版はGPUが必須なのでスマホでは動作しません。
どんなスペック・環境が必要ですか?
今回紹介したStable Diffusion WebUIを利用する場合、以下の条件のパソコンが必要です。
- WindowsまたはLinux
- 4GB以上のNVIDIA制GPU
- 8GB以上のRAM
- 10GB以上の空き容量(HDDやSSD)
上記条件はStable Diffusion 1.5系の軽量なモデルを使うときのもので、Stable Diffusion XL(SDXL)系のモデルを使う際はさらに高いスペックが要求されます。
Macのパソコンでローカル環境を構築したい場合は、ComfyUIなど別のツールを利用する必要があります。
インストール時にエラーになります
webui-user.batを実行してエラーになるときは、以下が原因の可能性が高いです。
- Pythonのパスが通っていない(インストール時のチェック付け忘れ)
- 別のバージョンのPythonが入っている
- パソコンのスペックが不足している
パスが通っていない場合は、インストーラーを再度実行してチェックを付ければ設定されるでしょう。
すでにPythonがインストールされていて複数のPythonが存在する場合は、コントロールパネルの環境変数でPathを編集して3.10を優先させたり、他バージョンを削除したりする方法があります。
おすすめのモデルは?
Stable Diffusion 1.5系のモデルは軽量かつ高速なので、はじめて利用する人におすすめです。
高画質な画像を生成したいのであれば、SDXLがベースとなっているモデルを選びましょう。
何のモデルがベースになっているかは、詳細画面の「Base Model」に記載されています。
迷ったときは、評価の高いAnything や Counterfeit などから使ってみてください。
画像に満足できない場合の改善策は?
プロンプトを洗練させたり、設定を変更したりして、イメージしている画像に近づけましょう。
一度の生成で満足できる画像を出力できる可能性はかなり低いので、結果を見ながら試行錯誤していきます。
設定できる項目やカスタマイズの幅はローカル版が優れているため、より良い結果を出したいのであればローカル環境の構築を検討してみてください。
使っているパソコンのスペックが足りなければ、クラウド上でローカル環境を利用できるConoHa AI Canvasの利用がおすすめです。

まとめ
本記事では、Stable DiffusionでLive2D用画像を生成する手順を解説しました。
- Stable Diffusionはテキスト入力だけで高品質画像を生成できる
- オンラインでもローカルでも無料から始められる
- オンライン版は手軽、ローカル版はカスタマイズ性が高い
- Live2D向けには白背景・正面構図がポイント
- GPUがない場合はConoHa AI CanvasなどクラウドGPUが便利
Stable Diffusionの柔軟性は、個性的なVTuberモデル制作の強力な味方です。
オンラインまたはローカル環境を活用して、あなただけのLive2DキャラクターをAIで生成してみてください。